

transformer
CNN
CONNOLUTIONAL NEVRAL NETWORK卷积神经网络
KERNEL:卷积核

训练:训练就是让网络根据已有的数据和它们的标签,自动确定卷积核中的数字
RNN
RNN(循环神经网络):重视序列过程
存在一个盒子记录数据输入的网络状态。
缺点:只能保留短期记忆,所以引出了LSTM
LSTM
LSTM:长短时记忆模型
门机制(GATE):用来决定信息如何保留的小开关,取值范围时(0-1),0是完全保留,1是完全舍弃
小盒子上有三个门
遗忘门:决定小盒子上保留多少原有的信息
输入门:决定当前网络有多少要被保存到小盒子中,记住那些新东西
输出门:决定了多大成都的输出小盒子中的信息
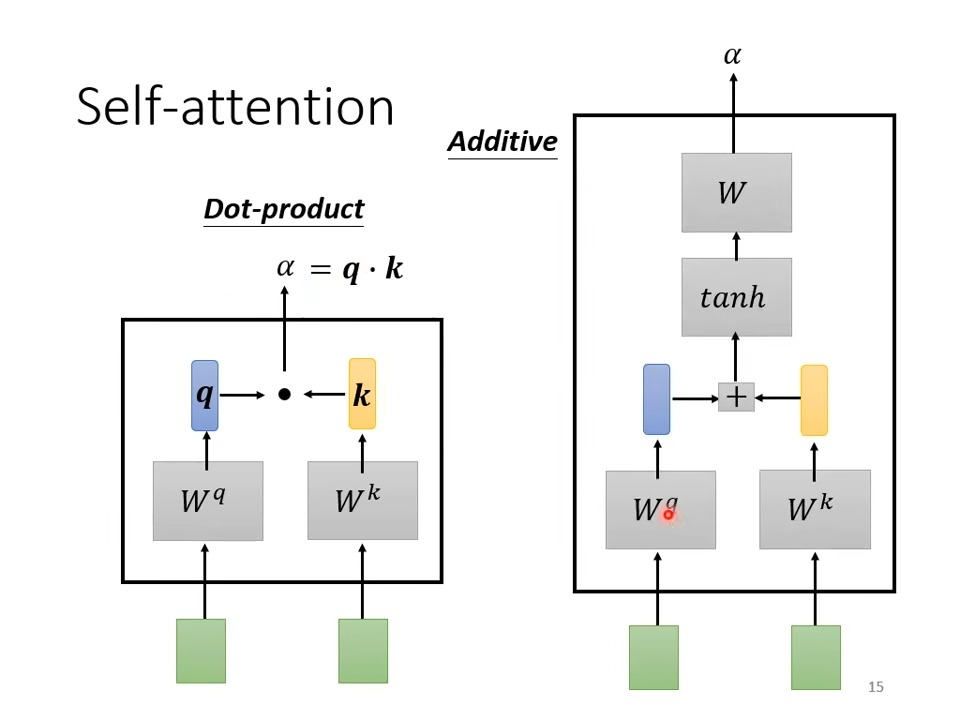
Attention
Q:QUERT:输入的信息
K:KEY 和 V:value成对出现:源语言,原始文本等已有的语言
分为 自注意机制 self-Attention 和 多种注意机制 Multi-Head-Attention
self-Attention
Input
sequence的输入视作一个向量,把单词都可以变为向量的序列,通过Word Embedding,可以看出相似语义的向量是聚集在一起的。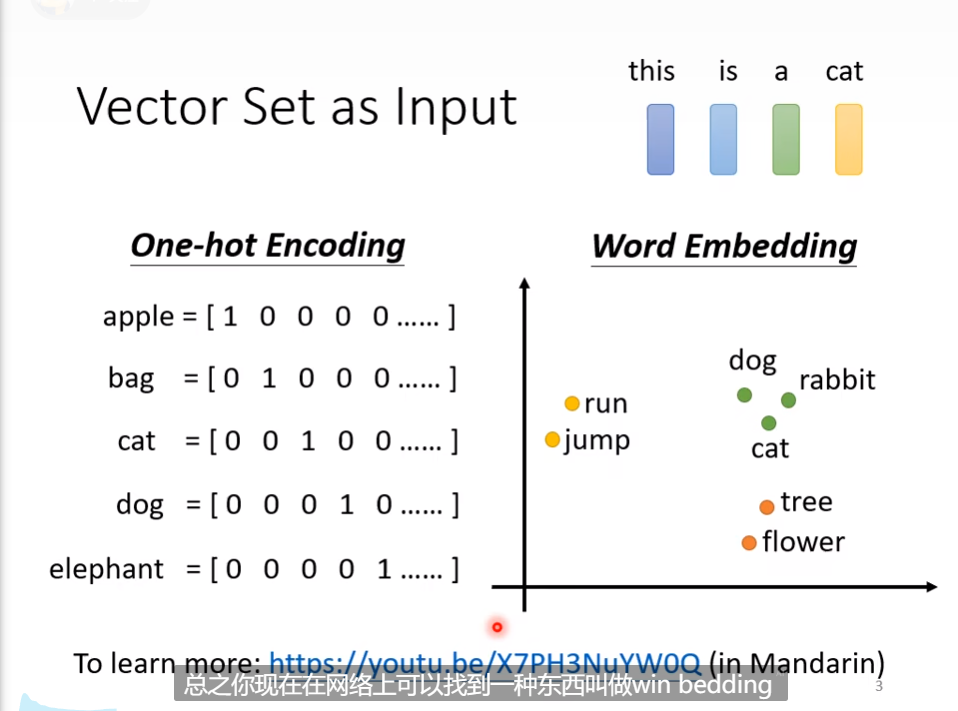
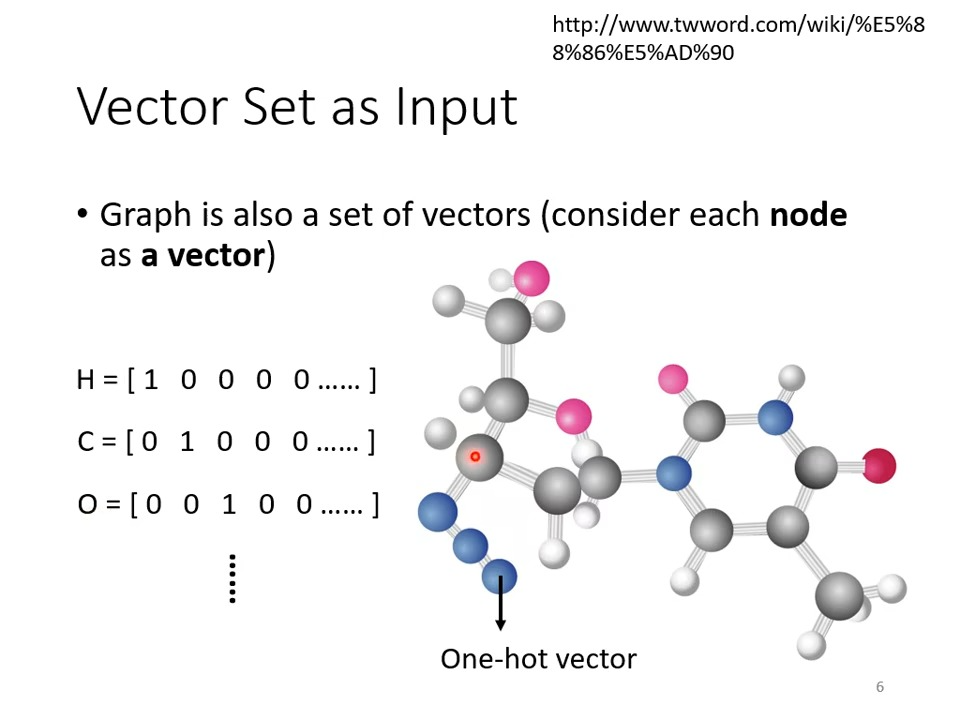
也可以把图看作输入:
output
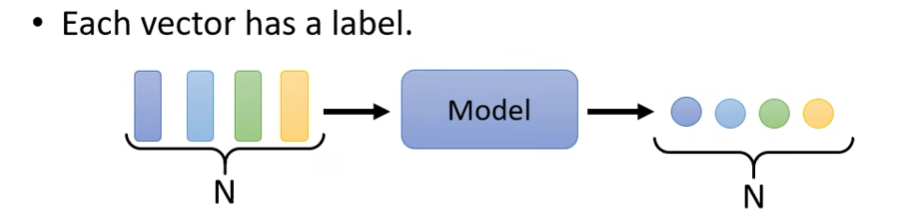
1.Each vector has a label输入个数和输出个数相同
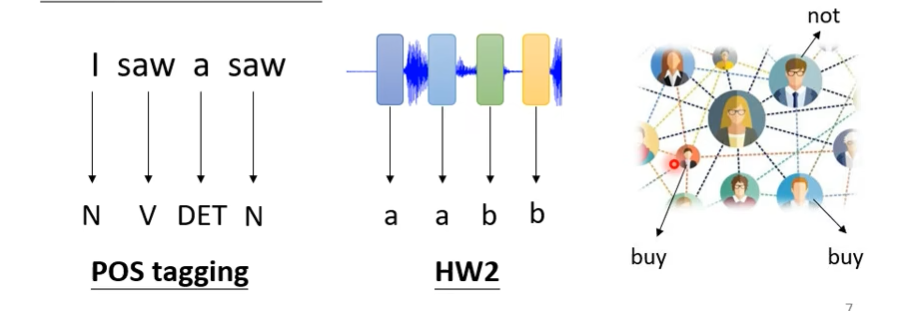
例子:
2.输出数目为1
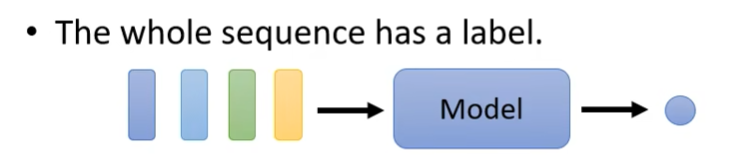
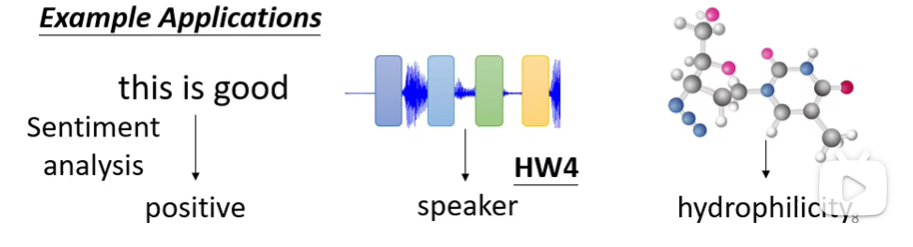
例子:
3.不知道应该输出有多少个
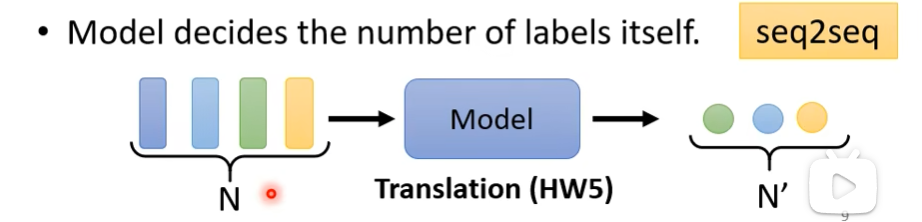
例如: 语言的翻译
Sequence Labeling
输入和输出的个数相同的情况下:
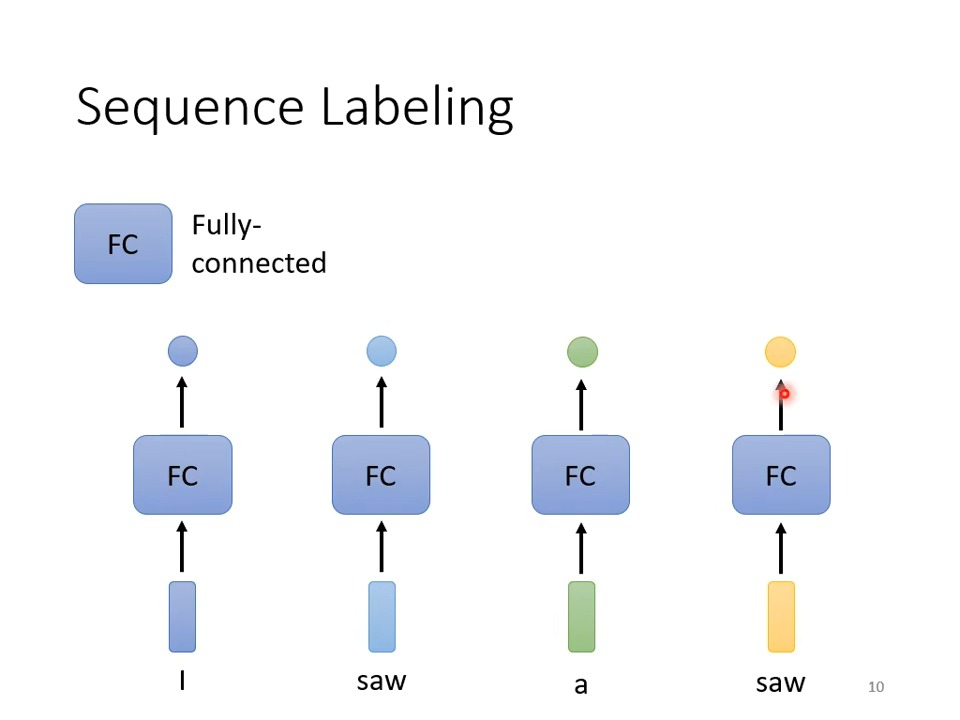
由于都是经过FC的处理,所以第二个saw和第四个saw的输出肯定是一样的,实际上这两个saw在语义和词性上都是不一样的,所以需要让这些单词向量联系上下文,单词与上下文的单词结合的序列称之为window,例如下图中第二个saw,他与I和a结合,所以window的长度为3(I saw a)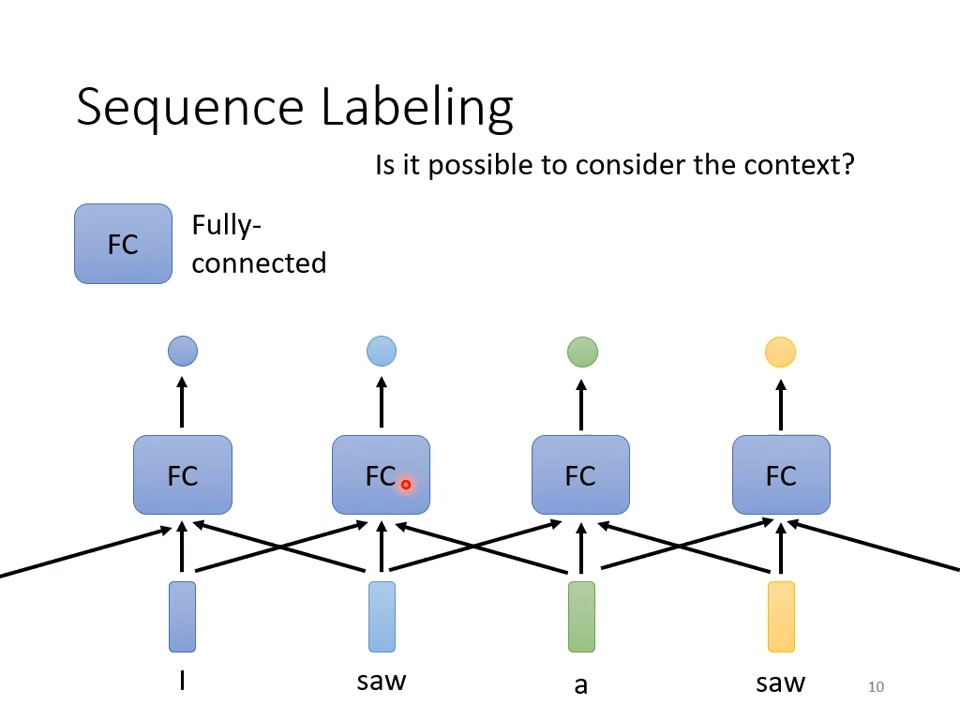
But How to consider the whole sequence?那如果需要考虑整个序列应该怎么办,有的人可能觉得把window盖住整个序列长度,但这也是不可行的,因为我们的序列长度都是可变的,如果保证window能盖住所有的序列长度,应该先把多段序列中最大的序列长度选出来,对window的要求过高,所以要用到self-attention,就是本标题要讲的东西.
Self-attention
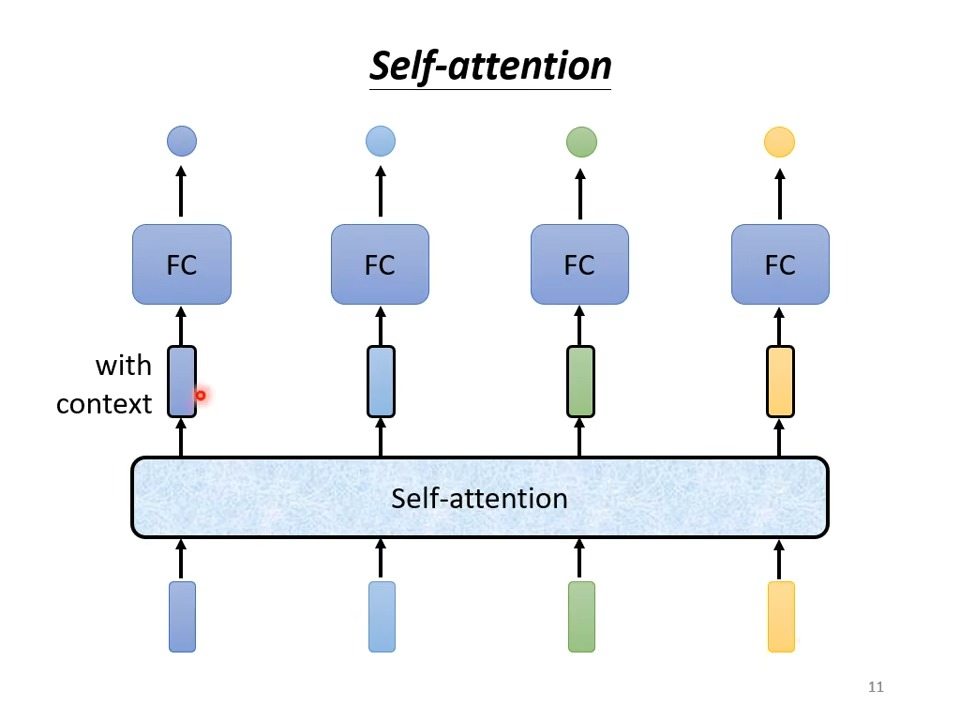
每个单词向量先经过self-attention对整个序列进行提取,然后再进行FC,所以每个FC都是考虑了整个sequence的咨询从而产生结果
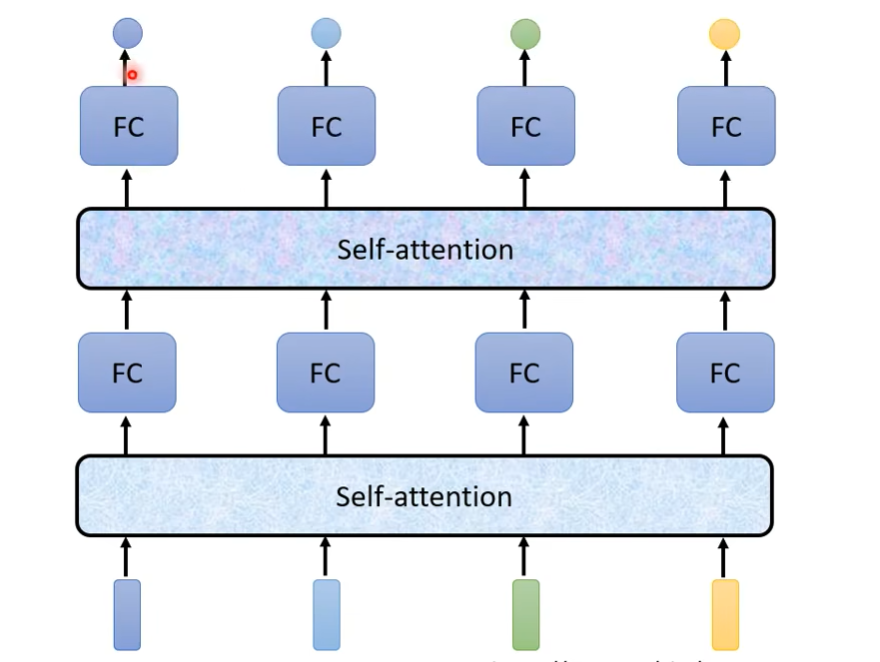
self-attention可以叠加使用
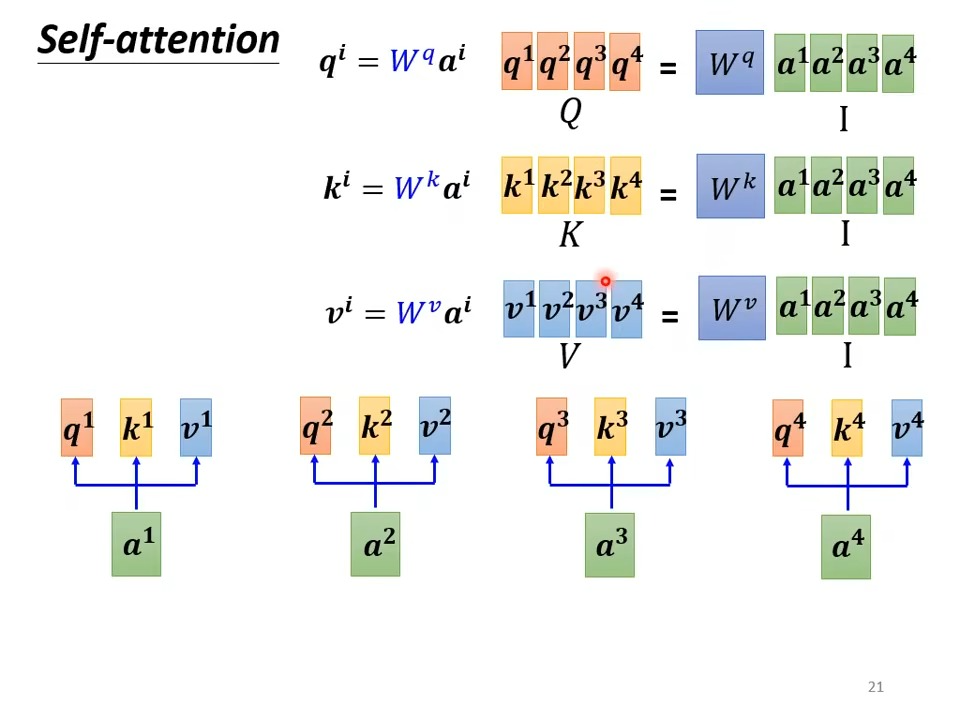
运行原理:
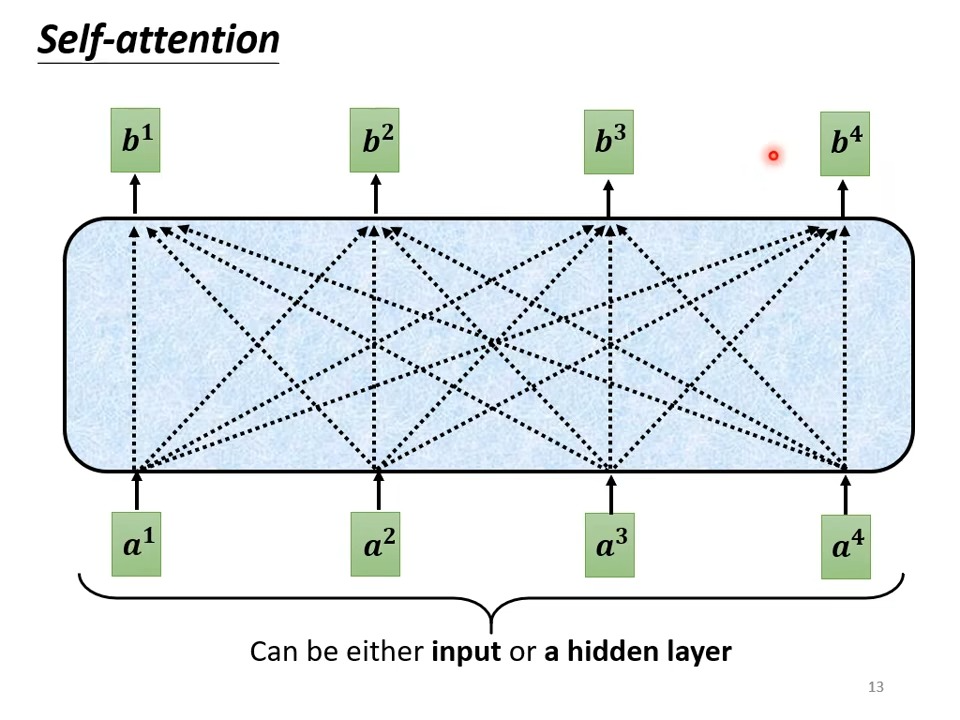
其中输入的a向量,不仅可以是原始序列,也可以是经过self-attention后的序列
怎么产生b1向量
根据 a1 Find the relevant vectors in a sequence,关联数值用α表示
从而得到b1


从矩阵的角度理解:


softmax之前的α向量

经过softmax后再与v向量进行相乘,得到b向量
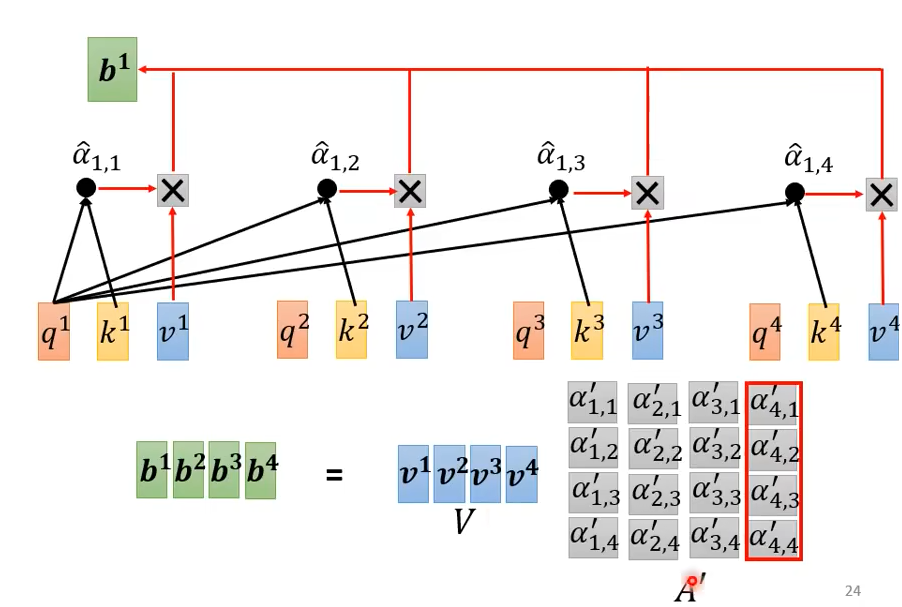
总结:
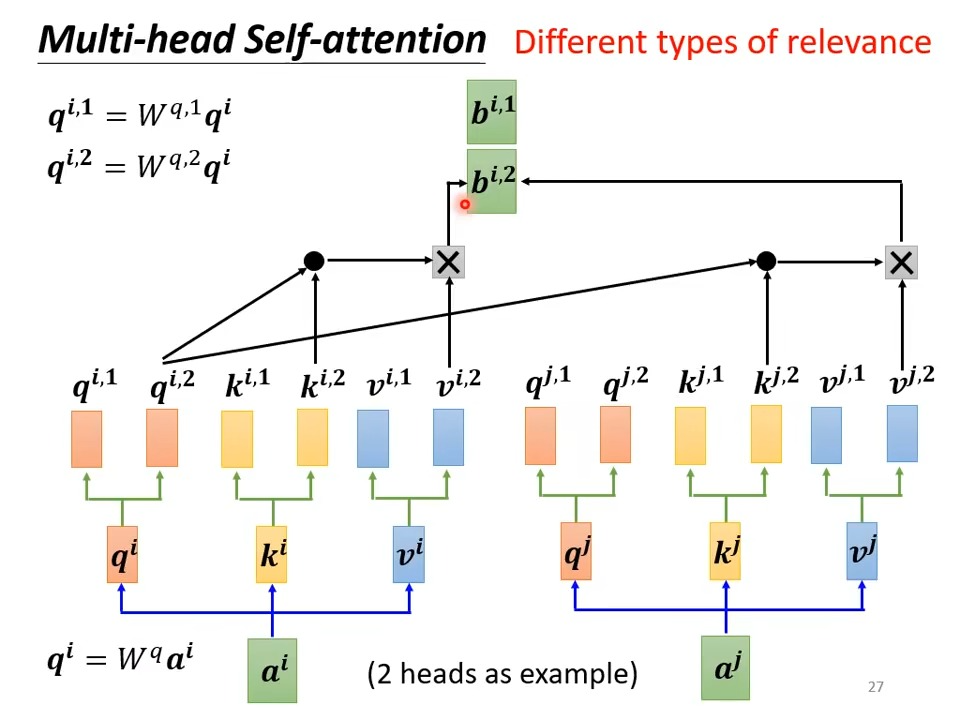
Muti-head Self-attention
操作如下,就是多个Q,V,K矩阵

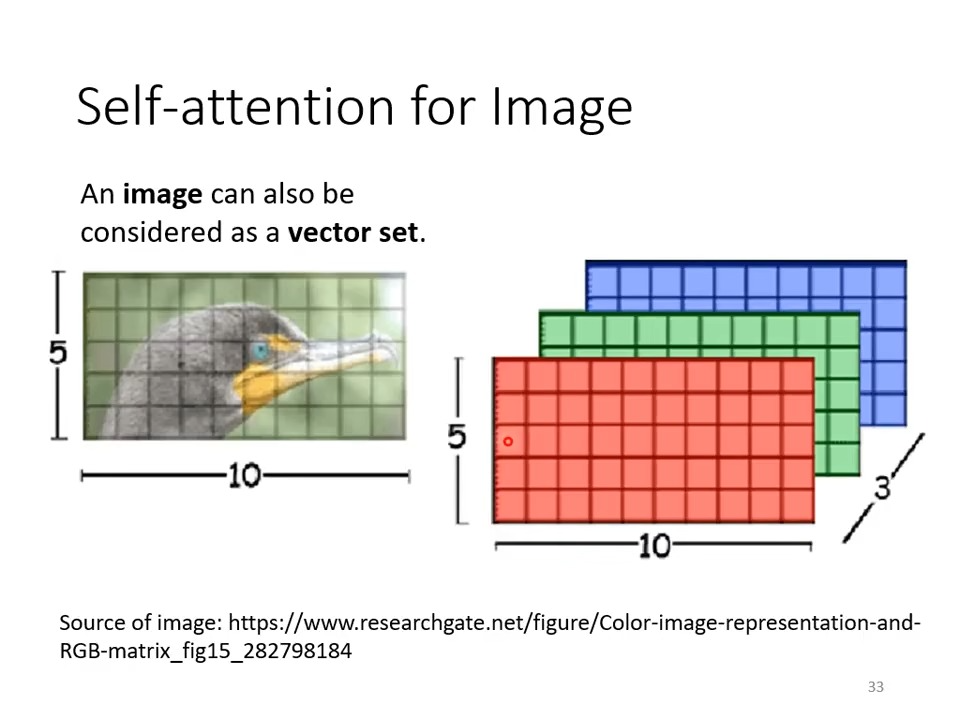
self-attention for image
把一张图片看做一个向量集,把每一块(最基本的像素块)看做3维的向量
transformer
1分钟简单了解
RNN 只能实现
N TO N
1 TO N
N TO 1
对N TO M类型问题没法很好的处理
于是引入 SEQ2SEQ
通过解码和编码,解决了两边长度不对等的情况
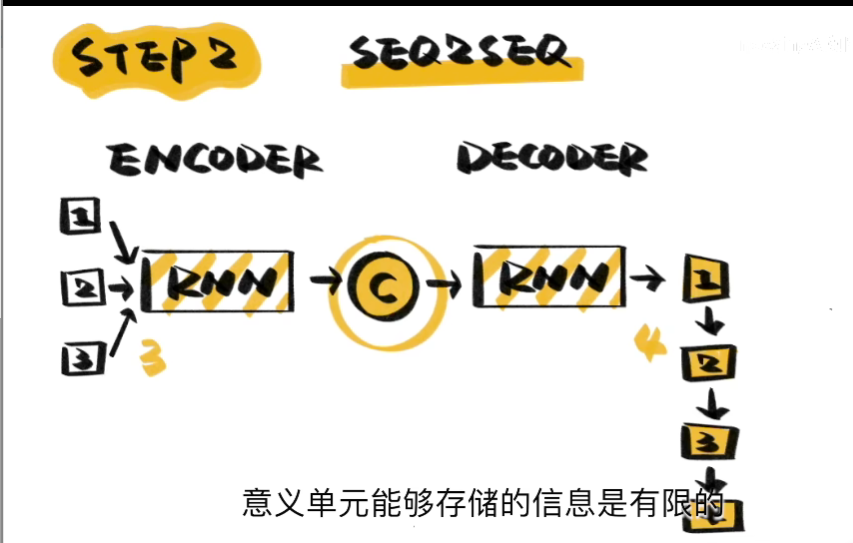
但是,当ENCODER一方的单词数目太多,则会使得翻译精度下降
于是引入ATTENTION在翻译的过程中提取有效信息
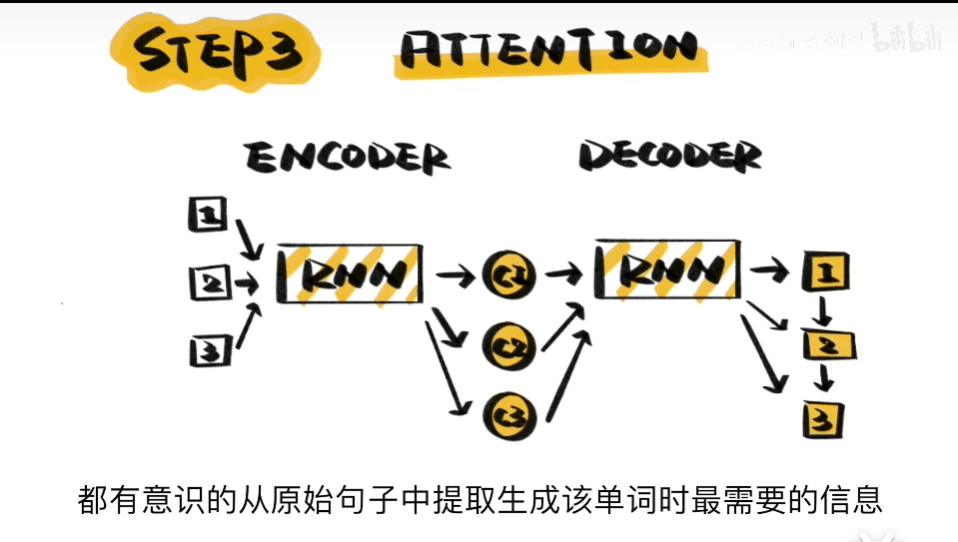
从而摆脱了输入序列的长度问题
进一步优化,提出了SELF-ATTENTION
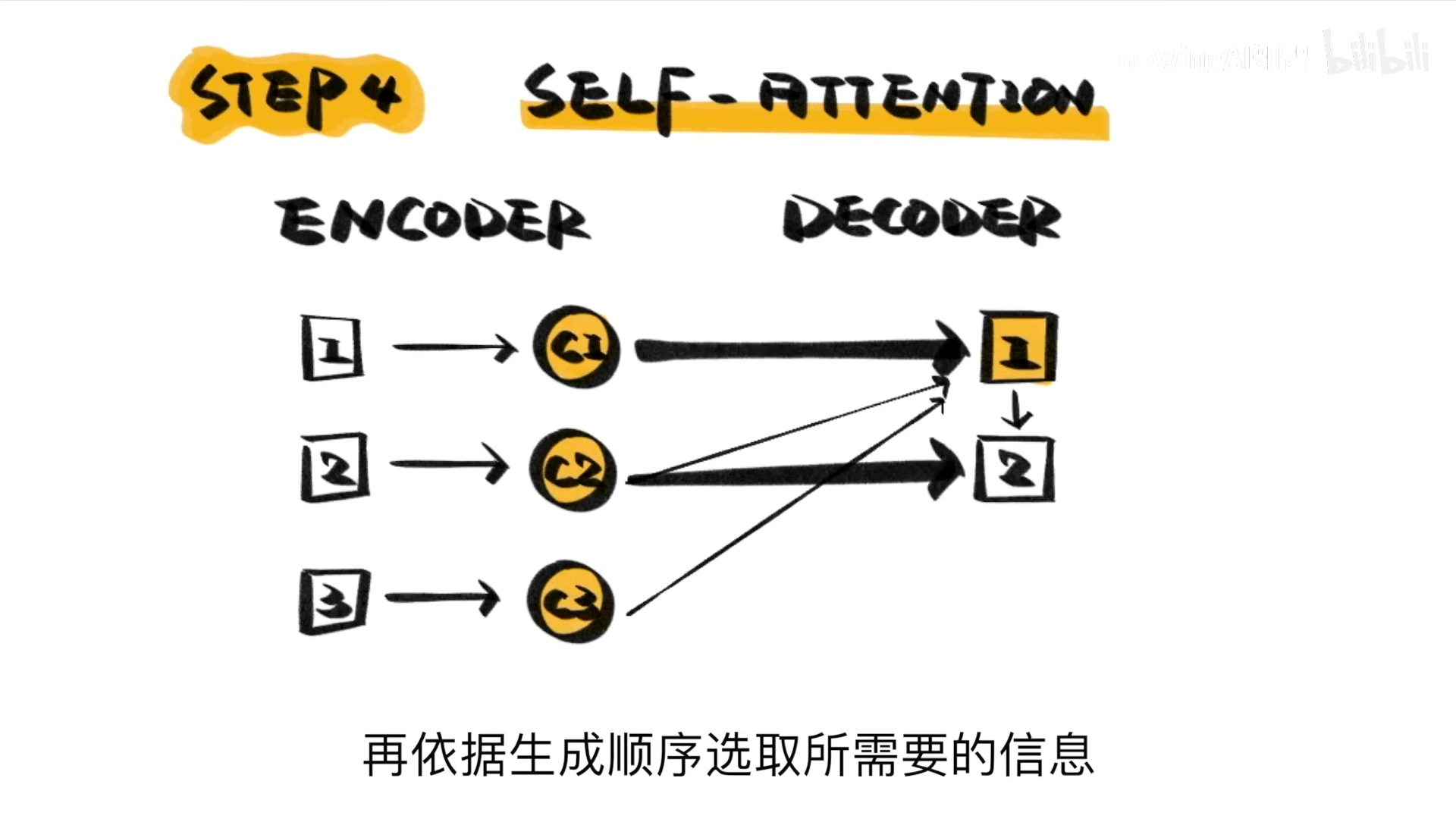
这就是transformer
transformer
Seq2seq: Input a sequence,output a sequence,但是不知道output多长
transformer就是一种seq2seq的model
例如:


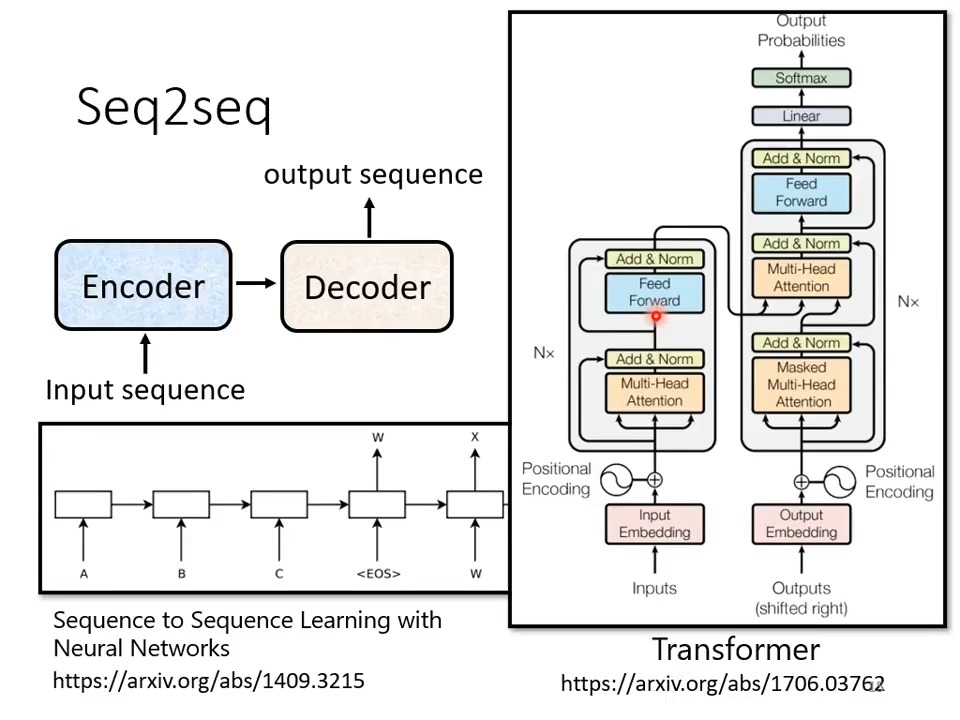
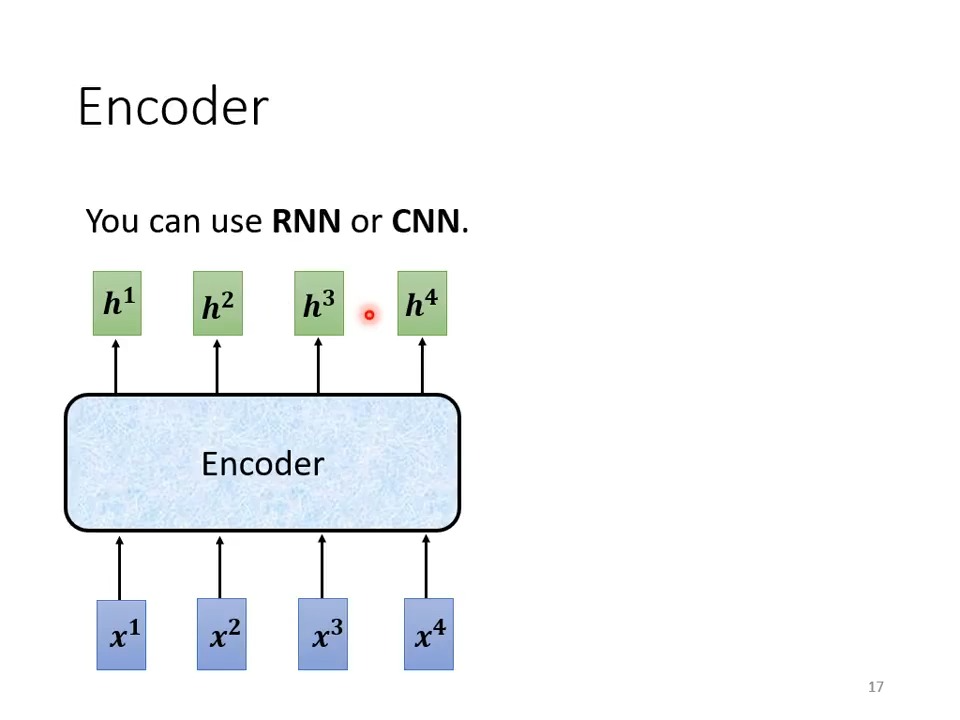
Encorder
Input set of vector and Output set of vector
什么模型可以做到呢? CNN,RNN self-attention,transformer都可以
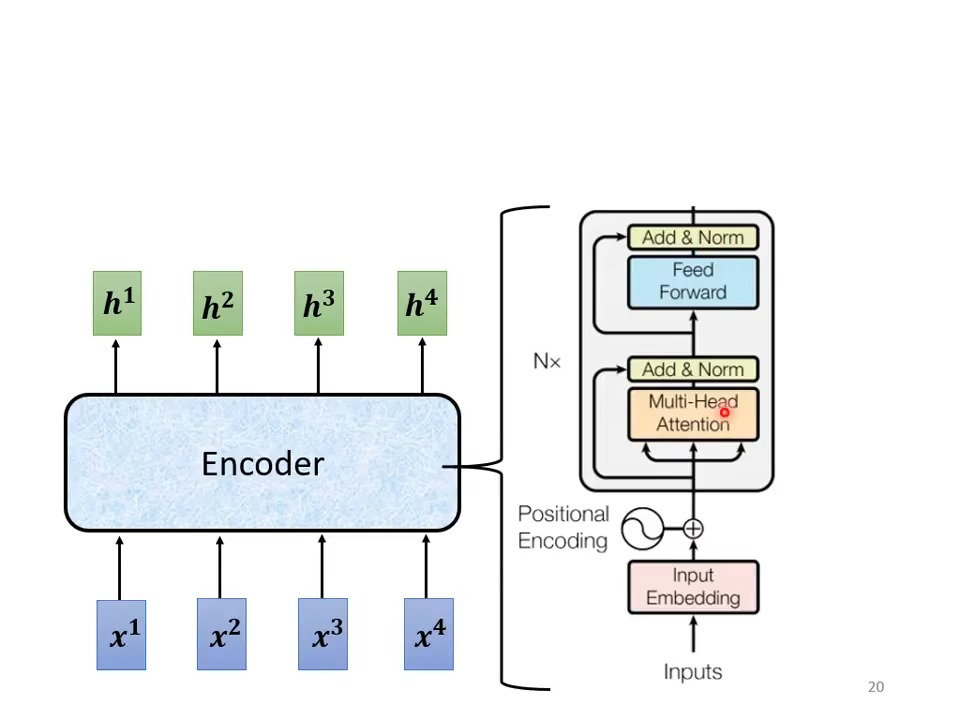
Encorder in transformer:
Decorder
Encorder的结果输入Decorder
Decorder 会把自己的输出当作下一个的输入,如果其中一个字出错了,下一个字需要根据错误的输入产生正确的输(要避免一步错,步步错)


对比发现,在Encorder上还有除了Add&Norm 和 Muti-Head Attention不同,其余部分是相同的,在从下网上的第二个部分,Decorder多了一个Masked的部分
Masked:
Masked self-attention

通过这个图片我们很容易看出,在self-attention中每一个a向量都要与其他所有的向量产生联系,从而产生对应的b向量,但是在Maked Self-attention中,第一个向量自己产生b1,其余向量只和前面的向量产生联系,例如,a2只和a1产生联系,a3只和a2,a1产生联系,a4和a3,a2,a1产生联系,这里产生联系的意思就是说会在一起经过Q,K,V的计算
(事实上,在解码的时候,向量a1,a2,a3,a4是依次放入的,所以每个向量a产生对应向量的时候只能考虑他左边的向量,而不能考虑右边的向量,因为这个时候右边的向量还没有放入🤣)
问题:由于decorder不知道我们output的长度,所以这种依次解码的工作会一直进行下去,那么该怎么在合适的长度的时候停止呢?
找一个END向量,END也是一种编码,当我们把所有的输入都decoder后,继续解码,通过decoder的运算,使得下一个是END的概率最大,然后输出END,就可以成功的解码
AT VS NAT

对于NAT Decoder: 可以一次性输出解码后的向量
BUT How to decide the output lenth for NAT decoder
把所有的begin都放入,然后输出向量先不管长度,我们只取输出向量END之前的句子
NAT 优点:
- 平行化(下一个单词的结果不需要上一个单词作为输入)
- 可以控制输出的长度
缺点:
NAT is usually worse than AT
Scheduled Sampling
前面提到,有可能出现一步错,步步错的情况,所以引入exposure bias也就是在训练的时候不能只输入正确的东西,也要输入错误的东西来训练,这样训练出来的模型,当需要错误的输入时,也能正确的输出

Beam Search
每次选择概率最大的路径(假设只有两种路径),也是局部最优和全局最优的关系

如何选择全局最优呢? 使用Beam Search




